华东师范大学软件工程学院实践报告
| 实验课程:数据库系统实践 | 姓名:刘佳奇 | 学号:10225101455 |
|---|---|---|
| 实验名称:Lab3 函数与存储过程 | 实验日期:2024/4/25 | 指导老师:姚俊杰 |
实验目的
通过对实际数据集操作体会python与sql的结合,以及熟悉数据库扩容等操作。
实验环境
- Vscode
实验过程与分析
Q1. 对数据集进行扩充
import os
def get_realpath(relative_path):
cwd = os.getcwd()
return os.path.join(cwd, relative_path)
KAGGLE_INPUT_PATH = get_realpath('datas/kaggle/input')
KAGGLE_WORKING_PATH = get_realpath('datas/kaggle/working')
def get_relativepath(realpath, basepath=KAGGLE_INPUT_PATH):
cwd = os.getcwd()
return os.path.relpath(realpath, basepath)
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
print('List files under KAGGLE_INPUT_PATH(', get_relativepath(KAGGLE_INPUT_PATH, os.getcwd()), '):\n')
import os
for dirname, _, filenames in os.walk(KAGGLE_INPUT_PATH):
for filename in filenames:
realpath = os.path.join(dirname, filename)
relative_path = get_relativepath(realpath)
print(' ', relative_path)
import sqlite3 as sql
from os import path
db_connection = path.join(KAGGLE_INPUT_PATH, "mubi-sqlite-database-for-movie-lovers/mubi_db.sqlite")
conn = sql.connect(r'E:\apps\Vscode\Python\Lab\datas\kaggle\input\mubi-sqlite-database-for-movie-lovers\mubi_db.sqlite')
# 读取最后10个数据
result1 = pd.read_sql_query("SELECT * FROM movies ORDER BY rowid DESC LIMIT 10", conn)
print(result1)
# 计算原始数据的行数
cursor = conn.cursor()
cursor.execute("SELECT COUNT(*) FROM movies")
num_rows = cursor.fetchone()[0]
print("Total number of rows in 'movies' table:", num_rows)
# 使用整个数据集的一半行数进行抽样
selected_data = result1.sample(n=num_rows // 2, replace=True, random_state=42)
# 保存选择的数据到原来的数据集
selected_data.to_sql('movies', conn, if_exists='append', index=False)
# 读取新数据集的前几行进行检查
result2 = pd.read_sql_query("SELECT * FROM movies ORDER BY rowid DESC LIMIT 10", conn)
print(result2)
# 计算原始数据的行数
cursor = conn.cursor()
cursor.execute("SELECT COUNT(*) FROM movies")
num_rows2 = cursor.fetchone()[0]
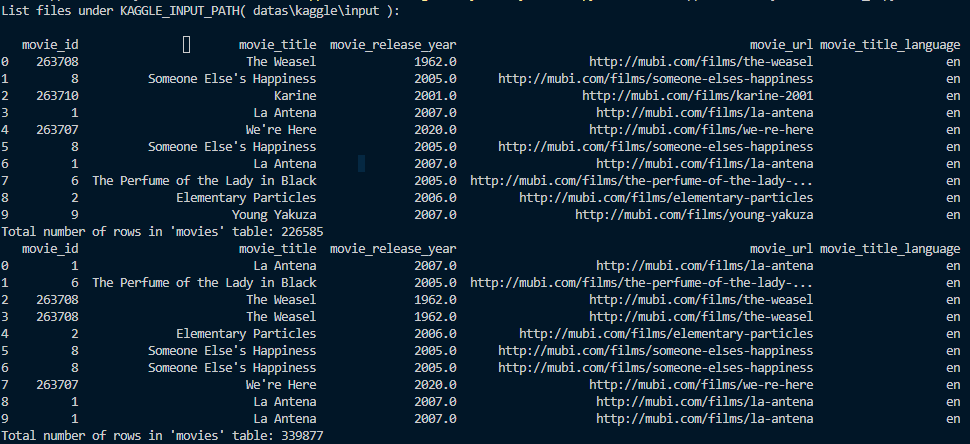
print("Total number of rows in 'movies' table:", num_rows2)在Pandas中,sample()函数用于从DataFrame中随机抽取样本。random_state设置随机种子保证每次抽取结果一致。随后将随机抽取的样本保存到原来的数据库。
运行结果:
Q2. 将扩容后的数据集减小1/4数据量
db_connection = path.join(KAGGLE_INPUT_PATH, "mubi-sqlite-database-for-movie-lovers/mubi_db.sqlite")
# 连接到数据库
conn = sql.connect(r'E:\apps\Vscode\Python\Lab\datas\kaggle\input\mubi-sqlite-database-for-movie-lovers\mubi_db.sqlite')
# 计算原始数据的行数
cursor = conn.cursor()
cursor.execute("SELECT COUNT(*) FROM movies")
num_rows = cursor.fetchone()[0]
print("Total number of rows in 'movies' table:", num_rows)
# 选择要保留的数据量(原始数据量的四分之三)
num_rows_to_keep = num_rows * 3 // 4
# 从数据库中随机选择要保留的数据
selected_data = pd.read_sql_query(f"SELECT * FROM movies ORDER BY RANDOM() LIMIT {num_rows_to_keep}", conn)
# 将所选数据保存到一个新的数据库表中
selected_data.to_sql('temp_movies', conn, if_exists='replace', index=False)
# 删除原来的 'movies' 表格
conn.execute("DROP TABLE IF EXISTS movies")
# 将临时表格 'temp_movies' 重命名为 'movies'
conn.execute("ALTER TABLE temp_movies RENAME TO movies")
# 读取新数据表的前几行进行检查
result = pd.read_sql_query("SELECT * FROM movies LIMIT 10", conn)
print(result)
# 计算调整后的数据的行数
cursor.execute("SELECT COUNT(*) FROM movies")
num_rows_adjusted = cursor.fetchone()[0]
print("Total number of rows in 'movies' table after adjustment:", num_rows_adjusted)从数据库随机选择要保留的四分之三数据,然后通过临时表格的媒介将原表覆盖。
运行结果: 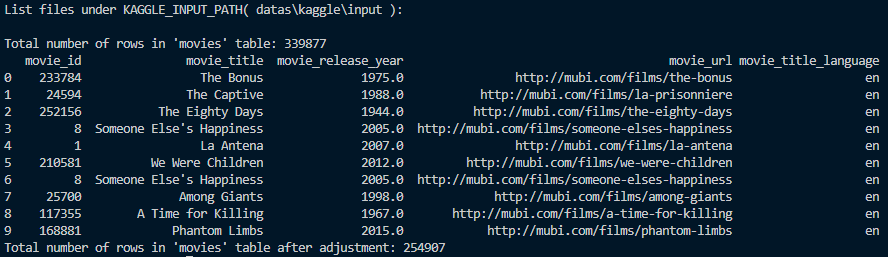
Q3. 实现嵌套查询
查找15年之后发行的电影的评论且title长度大于8。
# 执行SQL查询
query = """
SELECT *
FROM movies
WHERE LENGTH(movie_title) > 8
AND movie_id IN (
SELECT DISTINCT movie_id
FROM movies
WHERE movie_release_year > 2015.0
)
"""
result = pd.read_sql_query(query, conn)
# 打印结果
print(result)运行结果: 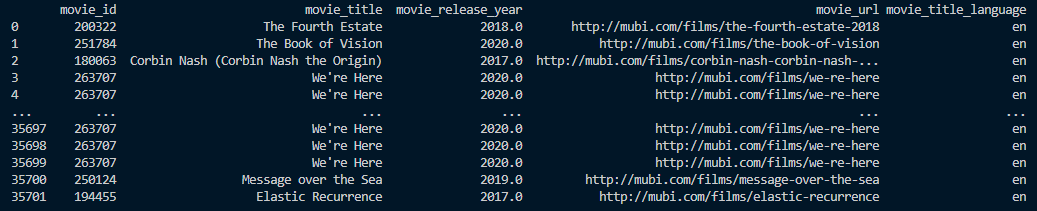
Q4. 同时使用group by语句和where语句进行查询
选取mocie_title大于8的影评,同时按照movie_release_year进行分组。
# 执行SQL查询
query = """
SELECT movie_title, movie_release_year
FROM movies
WHERE LENGTH(movie_title) < 8
GROUP BY movie_release_year;
"""
result = pd.read_sql_query(query, conn)
# 打印结果
print(result)运行结果:
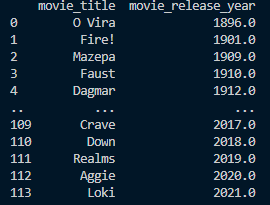
Q5. 关系代数式
一、 1. 获取最后10个数据
[ {} ({last_10} (_{True}(movies))) ] 其中,() 表示排序操作,() 表示重命名操作,() 表示选择操作。
- 计算原始数据的行数
[ _{} (movies) ] 其中,() 表示聚合操作。
- 抽样一半行数的数据
在 SQL 中没有直接的关系代数运算符来表示抽样,但我们可以通过以下关系代数表示要实现的抽样目标: [ _{*} ({} (movies)) ] 其中,() 表示投影操作,({}) 表示根据随机条件选择行。
- 保存选择的数据到原来的数据集
[ movies sampled_data ] 其中,() 表示并操作。
- 读取新数据集的前几行进行检查
[ {} ({last_10} (_{True}(movies))) ]
- 计算新的数据行数
[ {} (movies) ] 二、 1. 计算原始数据的行数: [ n {} (movies) ]
选择要保留的数据量(原始数据量的四分之三): [ m n ]
从数据库中随机选择要保留的数据: [ temp_movies _{*} (_{} (movies)) m ]
删除原来的 'movies' 表: [ movies ]
将临时表 'temp_movies' 重命名为 'movies': [ movies temp_movies ]
读取新数据表的前几行进行检查: [ _{*} ({top_10} ({True}(movies))) ]
计算调整后的数据的行数: [ new_n _{} (movies) ]
三、
[ result { ({} (_{ > 2015}(movies)))}(movies) ]
四、
[ result {} ({, } (_{}(movies))) ]
实验结果总结
结果归纳
- 对实际巨大数据集的扩容、缩小、查询等操作有了深入的了解。
- 对实际查询的SQL语句与关系代数式的对应有了深入的理解。
