最近心心念念想怀旧一波,重新读一下以前特别喜欢的一本小说,无奈发现存的txt完全找不到了。上网搜了一波,也是完全的搜不到,记得当年也是搜不到的,最后还是在贴吧一老哥那儿要来的txt版本。这次又在贴吧苦苦寻求,但要么有偿,要么不回消息。罢罢罢,还是自己动手,丰衣足食了。主打一手可持续发展(手动狗头
分析网页
这里以老公想看的如懿传为例(一个看过七八遍甄嬛传的1,好好好
在想要爬取的小说网页中,按F12看一下网页html的代码
随后找到小说的编码格式(一般都是utf-8,在head头里
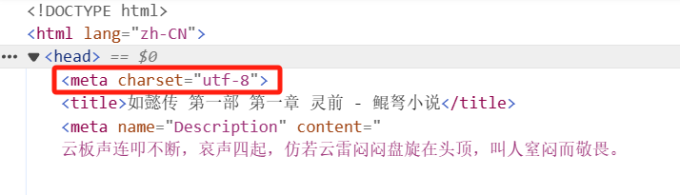 以及小说的具体内容。ctrl + shift + c
在页面中选择一个元素进行检查
以及小说的具体内容。ctrl + shift + c
在页面中选择一个元素进行检查 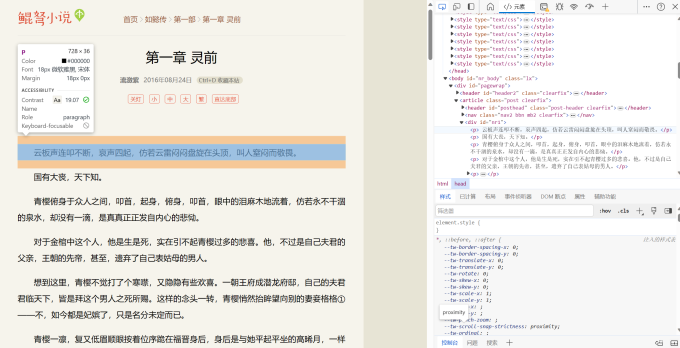 如图,我们想提取的内容都在p标签中
如图,我们想提取的内容都在p标签中
此外,找到下一章的内容具体在哪 
需要用到的库文件
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下哪个没安装对应pip install即可(这里re是系统库不用安
向网站发送请求
def main():
#小说的网址
baseurl = input("请输入小说第一章的网址,到后缀为止(如https://www.kunnu.com/):\n")
number = input("输入后缀(如ruyi/37892):\n")
url = baseurl + str(number) + ".htm"
#一般都是html,这个网站是htm,url对应修改即可
print("已完成爬取的章节:")
req = requests.get(url)
#上文我们已经看到是UTF-8的编码格式,这里照搬按此解析即可
req.encoding = 'UTF-8'
#解析得到网站的信息
soup = BeautifulSoup(req.text, 'html.parser')
print(soup)
os.system("pause")
if __name__ == "__main__":
main()运行一下试试  和预想的一样,soup就是这个网站的所有信息,接下来把想要的内容提取出来就行
和预想的一样,soup就是这个网站的所有信息,接下来把想要的内容提取出来就行
正则提取
提取标题
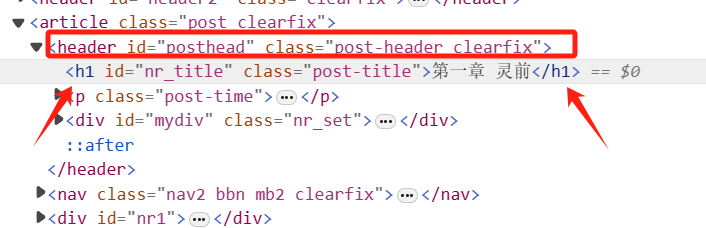 如图,这里我们找到h1标签中的标题,用beautifulsoup中的库函数进行提取
如图,这里我们找到h1标签中的标题,用beautifulsoup中的库函数进行提取
# 找到包含标题的h1标签
title_tag = soup.find('h1', id='nr_title', class_='post-title')
# 提取标题文本
title = title_tag.text.strip()提取正文

for item in soup.find_all('div',id = "nr1"):
end = item.get_text(separator="\n", strip=True)
# 使用get_text获取其中所有的纯文本findEnd = re.compile(r'<p>(.*?)</p>',re.S)
item = str(item)
end = re.findall(findEnd,item)实现跳转的逻辑
利用跳转的按钮
for section in soup.find_all('li', class_="next"):
link = section.find('a')['href']
url = link
#有些网站这里是省略号,只有后缀部分,那样就需要拼接一下保存信息到docx文件
几个必要的操作:
Doc = Document() #创建一个文档对象
Doc.add_heading(title,level = 0)
#写标题,Level从0到5是一级标题到六级标题
Doc.add_paragragh()超时重传
采用了最基础的try
req=requests.Session()
#访问https协议时,设置重传请求最多3次
req.mount('https://',HTTPAdapter(max_retries=3))
#5s的超时时长设置
req = requests.get(url = url, headers = head, timeout=5)
#如果超时,打印错误
except requests.exceptions.RequestException as e:
print(e)源代码
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下
def main():
Doc = Document()
#小说的网址
baseurl = input("请输入小说第一章的网址,到后缀为止(如https://www.kunnu.com/):\n")
number = input("输入后缀(如ruyi/37892):\n")
url = baseurl + str(number) + ".htm"
savepath = "./"+input("请为你的docx文档命名:")+".docx"
print("已完成爬取的章节:")
link = ""
req = requests.Session()
req.mount('https://',HTTPAdapter(max_retries=3))
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
while(link != "https://www.kunnu.com/ruyi/38266.htm"):
try:
req = requests.get(url = url, headers = head, timeout=5)
req = requests.get(url)
#上文我们已经看到是UTF-8的编码格式,这里照搬按此解析即可
req.encoding = 'UTF-8'
#解析得到网站的信息
soup = BeautifulSoup(req.text, 'html.parser')
# 找到包含标题的h1标签
title_tag = soup.find('h1', id='nr_title', class_='post-title')
# 提取标题文本
title = title_tag.text.strip()
print(title)
Doc.add_heading(title,level = 0)
for item in soup.find_all('div',id = "nr1"):
# item = str(item)
# end = re.findall(findEnd,item)
end = item.get_text(separator="\n", strip=True)
Doc.add_paragraph(end)
Doc.save(savepath)
#跳转到下一页
for section in soup.find_all('li', class_="next"):
link = section.find('a')['href']
# link = re.sub(r'^\.\.', '', link)
url = link
except requests.exceptions.RequestException as e:
print("出现异常,正在重试...")
os.system("pause")
if __name__ == "__main__":
main()其他小说网站都是异曲同工,重点分析源代码的容器、跳转等,改一改就好。
麻麻再也不用担心孩子找不到docx而发愁辣!
